Večina sistemov omogoča, da procesi leže kjerkoli v fizičnem pomnilniku. Čeprav se naslovni prostor računalnikovega pomnilnika začenja z naslovom 00000, je normalno prvi naslov uporabniąkega procesa drugače alociran. Preden postane nek program izvršljiv, mora preiti več korakov. Naslovi v programu so pri tem različno (v začetku lahko povsem simbolično) predstavljeni. Ti naslovi se nato transformirajo običajno v relativne naslove (relocatable addresses). Tako kodiran program je premestljiv glede na fizični pomnilnik. Program z absolutnimi naslovi ni tako fleksibilen.
Tipično lahko pride do asociacije (binding) naslovov programskih instrukcij in podatkov s pomnilniškimi naslovi v enem od naslednjih korakov:
Čas prevajanja (compile time): Absolutno programsko kodo tvorimo le, če vnaprej vemo, kje v pomnilniku bo moral ležati program oziroma njegovi podatki. Če želimo kasneje spremeniti lokacijo programa, ga moramo ponovno prevesti.
Čas nalaganja (load time): Prevajalnik je moral tvoriti relativno (premestljivo) programsko kodo. Če se spremeni začetni naslov, moramo program ponovno naložiti.
Čas izvajanja (execution time): Proces lahko premikamo iz enega v drug pomnilniški segment celo med izvajanjem. Asociacijo naslovov v času izvajanja programa omogoča aparaturna oprema.
Naslovu, ki ga glede na programski proces pripravi CPE računalnika, pravimo logični naslov. Naslov, kot ga vidi pomnilnik, pa je fizični naslov. Pri asociaciji naslovov v času prevajanja in času nalaganja so logični naslovi enaki fizičnim, pri asociaciji v času izvajanja pa se ti naslovi običajno razlikujejo. Logičnemu naslovu tedaj pravimo tudi virtualni naslov.
Primer: dinamična
realokacija
Koncept dinamičnega povezovanja (dynamic linking) je podoben dinamičnemu nalaganju. Namesto, da prestavimo v čas izvajanja nalaganje, prestavimo v ta čas kar povezovanje (na primer knjižnic). Zato binarna (izvršljiva) kopija programa ne potrebuje že navezanih sistemskih rutin. Binarni zapisi programov na disku so zato krajši. Namesto potrebnih sistemskih rutin imajo taki zapisi le ustrezne štrclje (stubs). Tak štrcelj je kratek košček programske kode, s katero proces locira zahtevano rutino v pomnilniku (če se ta že nahaja v pomnilniku), po potrebi pa zahteva njeno nalaganje s knjižnice na disku. Ta koncept tudi omogoča, da vsi procesi uporabljajo isto kopijo sistemske rutine v pomnilniku.
Dinamično povezovanje (sistemskih) knjižnic ima še eno prednost.Ko dobimo novo verzijo takih knjižnic, ni nujna ponovna predelava (povezovanje) uporabniških programov, saj bodo avtomatsko uporabljali novo verzijo. Da pa ne pride do nekompatibilne uporabe novih verzij zagotavlja informacija o zahtevani verziji, ki se nahaja tako v štrclju kot v knjižnici rutin. Starejši programi bodo pač še vedno uporabljali starejše verzije knjižnic. Takemu sistemu pravimo sistem skupnih knjižnic (shared libraries).
Primer: Ostranjevanje pomnilnika
Ne bomo se spuščali v same tehnike ostranjevanja pomnilnika. Navedimo
le algoritme, ki jih lahko uporabljamo pri odločitvah o zamenjavi strani:
 |
Naključna zamenjava strani
V zalogi strani naključno izberemo eno in jo nadomestimo z novo. Ta algoritem jemljimo le kot referenco za ostale. Kasneje bomo spoznali, da je to najslabša možnost. |
 |
FIFO algoritem:
Je najbolj preprost. Ko potrebujemo novo stran, izberemo v ta namen tisto ki je "najstarejša". Ta algoritem ni nujno najbolj optimalen. Tako lahko res zamenjamo stran, v kateri je tekel nek inicializacijski (in ne več potreben) modul. Lahko pa je v njej neka pogosto uporabljana podatkovna struktura. |
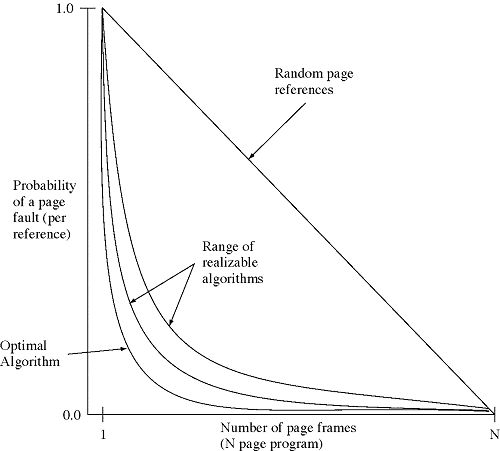 |
Optimalni algoritem:
Naj bi zamenjal tisto stran, ki povzroča najmanj izpadov strani (page faults). V praksi pa ga ne moremo implementirati, saj ne moremo vnaprej poznati, katere strani bomo potrebovali. |
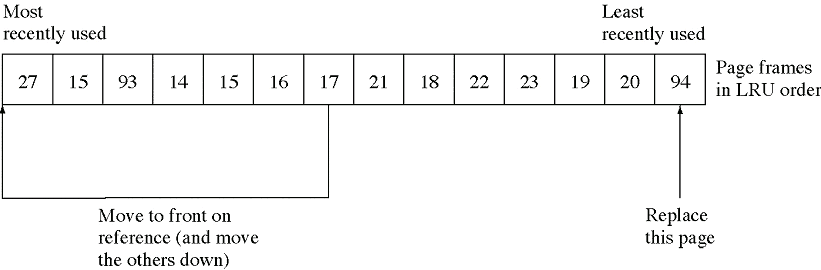
Je približek optimalnega algoritma. Za vsako stran vodimo evidenco, kdaj je bila nazadnje uporabljena. Ko potrebujemo novo stran, jo zamenjamo s tisto, ki je že najdlje nismo uporabili (Last Recently Used).
 |
Pogosto si pri tem pomagamo s takoimenovanim referenčnim
bitom (za vsako stran), ki se setira ob vsakem naslavljanju te strani,
Sistem pa ga periodično resetira.
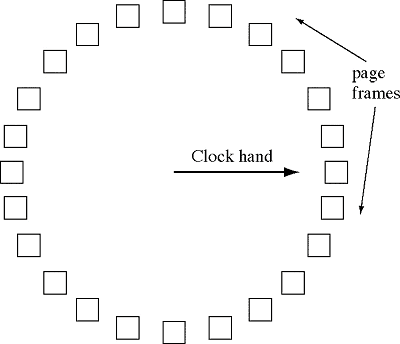
Poznamo več izpeljank tega algoritma. Ena od njih je urni algoritem, ko ciklično gledamo strani. Če ima opazovana stran referenčni bit (pravimo tudi umazani bit) enak 0, jo zamenjamo, sicer ne. |
Števni algoritmi: Temeljijo na tem, da za vsako stran štejemo število referenc te strani (v danem časovnem intervalu). Imamo lahko več strategij. Tako imamo lahko za kriterij, da zamenjamo tisto stran, ki je bila najmanj pogosto uporabljena (LFU, Last Frequently Used). Argument za tako izbiro je, da so najbolj aktivne strani tiste z največ referencami. Inverzen je algoritem MFU (Most Frequently Used), ki pravi, da take strani ne smemo ( takoj) zamenjati, saj morda še nima dovolj referenc, ker je bila vstavljena pred kratkim.
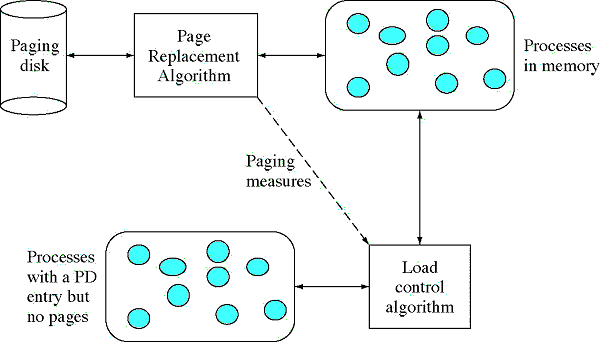 |
Krmiljenje bremena (Load control)
Odločiti se moramo, koliko procesov naj v danem trenutku sploh konkurira za strani. Če jih vzamemo preveč, bo prevečkrat prišlo do napake strani. Če jih je premalo, je pomnilnik slabo izkoriščen. Kot kriterij obremenitve je bolje,če opazujemo število napak strani kot pa obremenitev CPE. Opazujemo lahko tudi, koliko časa procesi čakajo na strani v pomnilniku.
|
Interaktivna demonstracija koncepta virtualnega pomnilnika