Jedro poizkuša minimizirati frekvenco dostopov do diska tako, da vzdržuje zalogo internih podatkovnih blokov, ki jim pravimo medpomnilnik (buffer cache) Te bloke vzpostavi med zagonom sistema. Medpomnilnik vsebuje podatke diskovnih blokov, ki so bili uporabljeni v bližnji preteklosti (recently used). Ko pride do zahteve za branje podatkov z diska, pogleda jedro najprej, če nima kopije teh podatkov v medpomnilniku. Sistem ima lahko tudi višjenivojske algoritme, ki omogočajo predčasno branje ali zapis podatkov, kar naj bi še povečalo propustnost.
Spomnimo se našega študijskega programa copy. Opisali smo, kaj se skriva za znanim sistemskim klicem read( ) . V nakazanem algoritmu te rutine smo imeli tudi vrstico
Beri podatkovni blok z diska v blok medpomnilnikaPoglejmo si rutino (naj ji bo ime bread( ) (block read)), ki opravi to nalogo:
bread( ) {
/* vhod: stevilka (naslov) bloka na disku */
/* izhod: vrne blok (v medpomnilniku) s podatki */
prevzemi podatkovni blok; /*to bo naredila rutina getblk */
if (podatki v bloku veljavni) return (podatkovni blok);
/* sicer pa se zgodi naslednje...*/
iniciacija branja z diska;
sleep (cakamo na konec I/O operacije z diskom);
return (podatkovni blok);
}
Vsak blok v medpomnilniku je pravzaprav sestavljen iz dveh delov: iz polja,
ki vsebuje podatke, ter iz zaglavja
(header), ki identificira blok, vsebuje pa tudi več kazalcev.
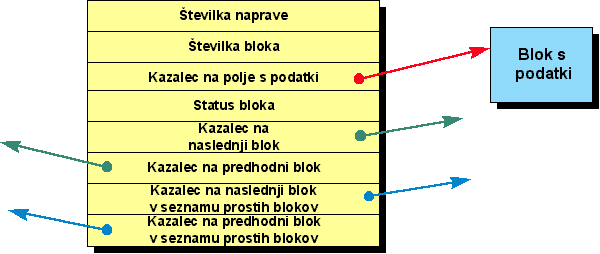
LINUX: Struktura zaglavja bloka medpomnilnika
Zaradi lažjega iskanja pomni sistem bloke (pravzaprav njihova zaglavja) v razpršenih seznamih, tako kot to prikazuje spodnja slika. S slike je razvidno še, da so prosti bloki dodatno povezani v seznam prostih blokov.
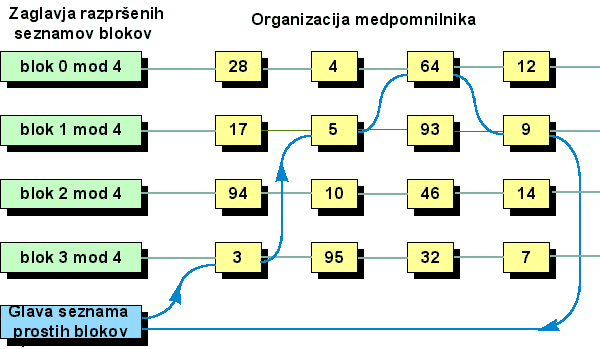
Ko jedro išče zahtevani blok, najprej pogleda, če je ta že v ustreznem seznamu. Če ga ne najde, poizkusi prevzeti prvi možen blok iz seznama prostih blokov. Tak blok nato uvrsti v (njemu ustrezen) seznam.
Zahtevani blok je nato uporabljen za branje (na primer v sklopu sistemskega klica read() ), ali za pisanje (na primer pri klicu write( ) ). Blok, ki naj bi bil zapisan, se ne zapiše takoj. V pričakovanju, da bo kmalu spet uporabljen, se le označi (status) da mora biti prepisan na disk (delayed write). Do samega zapisa pa pride šele, ko res sistem nujno rabi njegovo polje za kakšne druge podatke. Do zapisa vseh tako označenih blokov pride tudi ob zaustavitvi (shutdown) operacijskega sistema.
Oglejmo si še psevdo kodo algoritma za alokacijo podatkovnega bloka (dajmo ji ime getblk( ) ). To naj bi torej bila rutina, ki jo pokliče prej omenjena rutina bread( ).
getblk( ) {
/* vhod: stevilka periferne naprave, stevilka (naslov) bloka */
/* izhod: zaklenjen (zaseden) podatkovni blok, ki ga lahko uporabimo */
while (ne najdemo podatkovnega bloka) {
if (podatkovni blok v ustreznem seznamu ) {
if (podatkovni blok zaseden) {
sleep (cakamo na sprostitev bloka);
continue; /* se enkrat zaokrozimo v zanki */
}
zasedemo podatkovni blok; /* zapis v statusu */
umaknemo podatkovni blok iz seznama prostih;
return (podatkovni blok);
}
else {
/* v ustreznem seznamu ni podatkovnega bloka */
if ( na seznamu prostih ni nobenega podatk. bloka ) {
sleep (cakamo na pod. blok v seznamu prostih);
continue;
}
umaknemo podatkovni blok iz seznama prostih;
if (podat. blok zaznamovan delayed write) {
asinhroni prepis podatk. bloka z diska;
continue;
}
umaknemo podatk. blok iz starega seznama;
vstavimo podatk. blok v ustrezni seznam;
return (podatkovni blok);
}
}
Iz podanega algoritma je razvidno, da pride do dejanskega, fizičnega prepisa
naslovljenega bloka iz diska v podatkovni blok medpomnilnika (ali obratno)
le v skrajnem primeru, ko ne gre drugače. To pa je že problematika nizkonivojskih
rutin gonilnikov.